怎么判断一条 SQL 到底慢在哪?NineData SQL 智能优化能解决什么

SQL 变慢最怕的不是慢本身,而是大家一开始只能靠猜。明明语法没报错,业务一上线却卡住了;多了一个函数、少了一个索引,或者关联顺序不合适,就可能让数据库白白扫描一大堆数据。在很多团队里,这类问题最早往往会被归到SQL工具的日常使用体验里,但真正决定排查效率的,还是能不能尽快把执行代价拆清楚。
问题在于,“SQL 慢”这三个字太宽泛。到底是扫描太多、排序太重、关联被放大,还是索引因为写法失效了?如果没有一个更直接的分析入口,排查时间很容易被拖长。
NineData 的 SQL 智能优化,就是拿来处理这类问题的
NineData SQL 智能优化会做哪些事情?
1. 分析目标 SQL 背后的风险
在 NineData SQL 窗口里,可以直接针对当前 SQL 发起智能优化分析。平台会结合 SQL 本身、数据库类型、表结构、索引信息和常见性能风险,给出更容易理解的优化建议。
它不只是简单给出一句提示,而是会尽量把问题说明白:
当前 SQL 可能带来什么影响。
为什么会出现全表扫描、排序开销、关联放大等问题。
哪些写法可能导致索引失效。
哪些索引或 SQL 改写更适合当前场景。
优化建议应该如何分步骤落地。
对不熟悉执行计划的开发人员来说,这样的分析能把很多原本需要 DBA 先介入判断的问题,转成更直观、可理解、也更容易落地的建议。
2. 给出优化路径
发现 SQL 慢只是起点,真正有价值的是告诉用户下一步该怎么改。如果把它放到带SQL审核的数据库管理工具这类方案里看,一个合格的能力不该只会执行 SQL,还要能把风险判断、修改方向和后续验证路径交代清楚。
NineData SQL 智能优化会根据不同场景给出相应建议,例如:
对字段类型不匹配的问题,提示修正查询条件写法。
对索引缺失的问题,给出更匹配查询条件和关联字段的索引建议。
对索引列使用函数的问题,提示是否可以改写 SQL,或使用表达式索引。
对窗口函数、聚合查询、排序查询,分析是否需要复合索引或改写查询方式。
对统计信息过期的问题,提示更新统计信息,让数据库优化器重新选择更合理的执行计划。
这类建议会尽量落到用户看得懂、评估得了、也能继续执行的方向上。
真正有用的,不只是看见慢
如果只看表面,很多人会把 SQL 智能化理解成“AI 帮我看看 SQL”。可一旦放进真实生产问题里,光看一眼显然还不够。从AI SQL优化的角度说,问题不在于多给几条经验规则,而在于能不能把执行代价和改写后的效果放到同一套判断里。
NineData 是沿着 CBO 代价、运行态信息、索引推荐、SQL 改写和效果验证这些方向继续往下做。它想回答的是:问题为什么出现、应该怎么改、改完以后有没有真正变好。
1. 不只看规则,还会看 CBO 代价
这里有个很关键的前提:SQL 优化不能只靠静态规则。
同样一条 SQL,在 1 万行表上和 1 亿行表上不是一回事;同一个索引,在不同数据分布下效果也可能完全不同。
所以 NineData SQL 智能化不只做静态检查,还会把执行计划、数据分布和统计信息这类运行态信息一起纳入分析,这正是 CBO 代价分析更有价值的地方。
数据库最终会选择哪条执行路径,本质上还是看优化器估算下来哪条路径代价更低。SQL 智能化就是顺着这个逻辑,把“为什么慢”继续往下拆。
比如一个 JOIN 慢,问题可能是驱动表选错了、关联列缺索引、统计信息不准,或者前面过滤条件没有先把数据量筛选下来。普通规则很容易只看到表面,CBO 代价能更接近真实执行现场。
2. 索引推荐和 SQL 改写,要一起看
还有一个很容易被忽略的地方:优化建议不能只停在 “建议加索引”。
真正要落地,至少要回答几个问题:
这个索引是为了过滤、关联,还是为了排序?
SQL 改写之后,结果是不是还是同一批数据?
新的执行计划有没有变好?
预估执行时间是不是真的下降了?
NineData SQL 智能化会把索引推荐和 SQL 改写放在一起判断。能通过索引改善的,就给出索引方向;如果问题更多出在 SQL 写法本身,比如子查询重复执行、条件下推不充分、窗口函数排序代价过高,也会进一步给出改写思路。
但 SQL 改写不能走得太激进。跑得更快却把结果改错了,那不是优化,而是事故。所以语义准确性必须放在前面,尤其是复杂 SQL,宁可保守一些,也不能为了追求“看起来更快”把结果集改坏。
3. 改完还要验证,别靠感觉
更实用的一点在于,它还会继续对优化方向做效果评估:新的执行计划大概会是什么样,执行成本有没有下降,预计耗时是否出现明显变化。这样开发或 DBA 就不必完全靠经验再猜第二轮。
这一步其实能省下很多时间。以前做 SQL 优化,往往是先猜一个改法,跑一下,不行再改,再跑一轮。碰到复杂 SQL,这样反复试会非常消耗。NineData 把执行计划、预估耗时和索引效果放到一起看,相当于提前做了一轮数字化验证。对持续处理线上问题的团队来说,数据库自动化运维的价值不只是多一个功能入口,而是能不能把诊断、验证和复盘串成一条顺手的工作链路。
很多复杂 SQL 一旦把错误的全表扫描、重复排序、低效关联路径拉回来,性能提升不是一点点。诊断和优化效率也会跟着上来,因为少了很多无用的尝试。
还有一个容易被低估的价值:语义准确性。复杂 SQL 改写最怕 “跑得更快,但结果不一样”。NineData 在给改写建议时,会把原 SQL 语义放在前面,尽量避免为了优化而优化。
开发、DBA、运维都能从中省时间
开发人员:可以在提交 SQL 前提前发现风险,减少低效 SQL 进入生产环境的概率。
DBA:可以减少重复性的初步诊断工作,把更多精力放在复杂问题判断、索引治理和容量规划上。
运维团队:当业务出现响应变慢、数据库负载升高、查询超时等问题时,SQL 智能优化可以帮助团队更快定位可疑 SQL 的问题方向,缩短排查时间。
更重要的是,它把 SQL 优化从“少数专家的经验活”慢慢变成“团队日常也能使用的能力”。即使团队里不是每个人都熟悉执行计划,也可以借助 NineData 拿到相对清楚的分析结果和优化建议。
上手门槛并不高
SQL 智能优化已经集成在 NineData SQL 窗口里,不需要再额外安装工具,也不用把 SQL 复制到别的平台单独分析。
使用方式很直接:
1. 打开目标数据源的 SQL 窗口。

2. 选中需要分析的 SQL,单击SQL 智能优化图标。
3. 查看系统返回的分析结果,并结合业务场景决定是否调整 SQL 或索引。
整个过程不会直接替用户修改或执行 SQL,而是返回分析结果和优化建议。涉及生产环境的 SQL 调整,依然建议先在测试环境验证,再按团队规范发布。
最后
真正有效的优化,前提还是先看清 SQL 为什么慢、会带来什么影响、又该从哪里改起。NineData SQL 智能优化要做的,就是把这条路径缩短一些,也解释得更明白一些。对私有化部署的数据库管理平台来说,SQL 诊断如果能直接落在同一平台里,开发、DBA 和运维后面的协作衔接通常会更顺。
下一次再遇到 SQL 突然变慢,先让 NineData 帮你把问题看透一点。
关于 NineData
NineData 是玖章算术(浙江)科技有限公司旗下智能数据管理平台,专注于云计算与数据管理基础技术创新,依托云原生架构与 AI 能力,打造覆盖数据库 DevOps、数据复制、数据对比、智能运维等核心场景的一体化数据管理平台,帮助企业在多云、混合云及复杂异构环境下实现更高效、更安全、更智能的数据管理。
NineData 面向企业数据库开发、迁移、同步、治理与运维全流程,提供从研发协同到生产保障的完整能力支撑,助力企业提升数据流转效率、强化数据安全与合规治理,加快数字化升级与全球化业务落地。产品已广泛应用于金融、制造、能源、电力、互联网、医疗健康、跨境出海等多个行业场景。
审核编辑 黄宇
相关文章
-
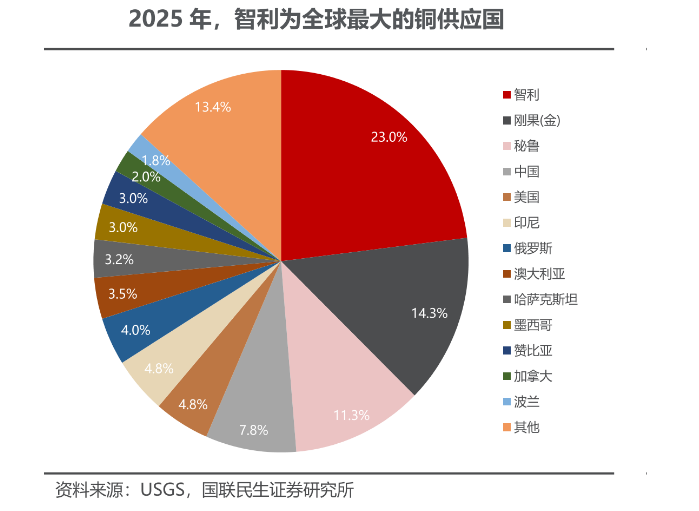
实探厄尔尼诺“风暴眼”:极端天气“惊扰”铜市 冲击有多大?
-

明天,港股迎来重要调整
-
近期股价大涨超46%!电解铝龙头宏桥控股公告,拟定增募资不超120亿元
-

地方养老基金2025年投资收益率5.76% 社保基金会:积极把握资本市场回调机会
-

上海市国资委部署建设大宗商品贸易投资平台
-
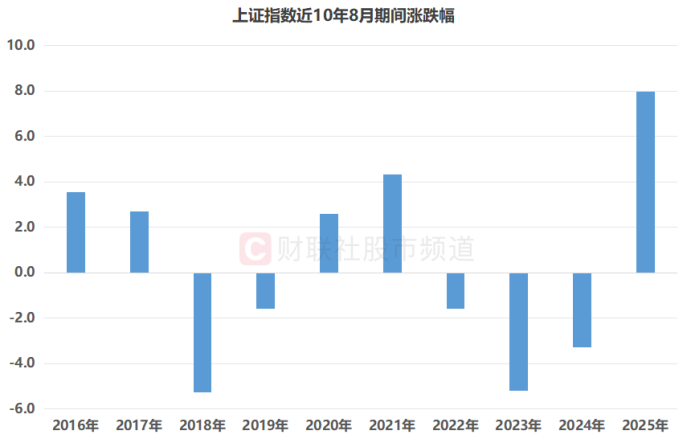
中报“大考”倒计时!复盘近十年8月行情 哪些板块历史表现较佳?
-

抵制国际足联逼售“世界杯股权” 欧足联:我们不踢了
-
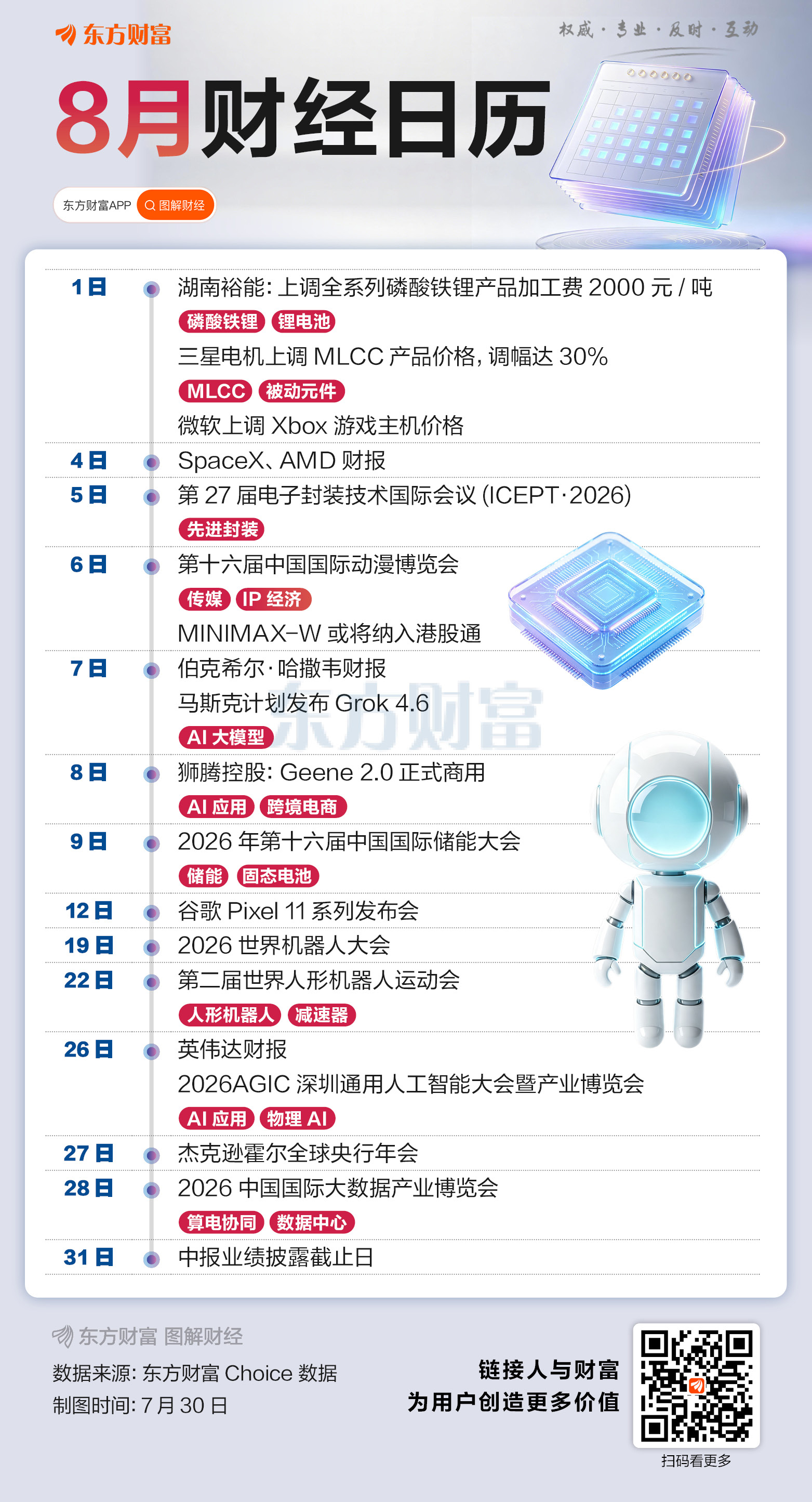
八月财经日历来了!重点关注中报业绩