是什么技术让小鹏智驾敢扔掉激光雷达?

[首发于智驾最前沿微信公众号]2024年10月,小鹏汽车在1024科技日上宣布了一个重要的技术决定,今后的新车型将全面取消激光雷达,全线切换至纯视觉智驾方案,这一转变随后在小鹏P7+、MONA M03、新款G6、G9、X9等车型上逐一落地。到2026年,小鹏已将所有在售车型的智驾系统统一在纯视觉路线之上。从行业普遍堆硬件到主动做减法,小鹏的技术底气究竟来自哪里?

算力够了之后,纯视觉为什么反而更强?
纯视觉方案的基本原理决定了它对算力的需求远高于激光雷达方案,激光雷达直接输出三维点云数据,系统拿到的是已经结构化的空间信息;而纯视觉只拿到二维图像,需要从中推断出三维世界的深度、形状和运动状态。这个从二维还原三维的过程,本质上就是一个巨大的数学求解问题,需要极强的并行计算能力。
何小鹏在2025年的一次采访中直截了当地解释了技术方案转变的原因,过去,纯视觉方案表现不佳主要是因为算力不足,视觉系统看到的图像既没有足够的像素点阵,也没有足够的帧率和时空逻辑。随着算力的大幅提升,这一问题得到了解决。这不是一个渐进式的改善,而是一个从做不了到做得到的质变。
算力为什么这么关键?其实可以从一个具体的场景来理解。当车辆以60km/h的速度行驶时,每秒钟前进约17米。纯视觉系统需要在这一秒之内完成从多路摄像头获取高分辨率图像,在多帧之间建立时序关联,将二维像素转换为三维空间中的物体和可通行区域,判断各物体的运动意图,生成安全的行驶轨迹,然后输出方向盘转角、油门和刹车指令。这一整套流程如果超过100毫秒,车辆就已经移动了近两米,在复杂路况下可能是致命的。
图片源自:网络
激光雷达方案之所以在早期更有优势,就是因为它跳过了从图像推断三维这一步,直接给系统提供了较准确的空间信息,减少了对算力的依赖。但当车端算力足够大之后,纯视觉的这条绕远路的方案反而变成了优势,因为它看到的是更原始、更丰富的信息,没有经过激光雷达点云的简化处理,理论上能够识别更多类型的物体和场景。
小鹏在纯视觉方案上的应对方式是在车端部署了远超行业主流水平的算力,以全新小鹏P7为例,全系搭载三颗自研图灵AI芯片,整车有效算力达到2250 TOPS。在这个配置中,两颗芯片驱动智驾VLA大模型,另一颗协同高通8295P芯片驱动座舱大模型。
作为对比,目前市场上多数同价位车型的智驾算力在几十到几百TOPS之间。即便是12.98万元起售的小鹏MONA M03 Max版,也配备了单颗图灵芯片750 TOPS算力。在Robotaxi方案上,小鹏更是搭载了4颗图灵芯片,车端算力达到3000 TOPS,为L4级别的能力提供了硬件裕量。

自己造芯片,和买通用芯片有什么不同?
算力差距只是表象,小鹏选择纯视觉更底层的原因是芯片的性质变了,小鹏在2024年8月完成自研图灵AI芯片的流片,2025年第二季度实现量产上车。这颗芯片的意义,不只是一颗更快的Orin,而是一种不同的设计逻辑。
英伟达Orin系列走的是通用计算路线,本质上是一颗车载GPU,提供标准化的算力,各车企自行在上面部署算法。这套模式的优势是生态成熟、软件支持完善、适配多车企;其劣势是算力利用效率受限于通用二字,芯片中有一部分计算资源会被分配给智驾实际并不需要的任务类型。
小鹏走的则是算法定义芯片路线,从自己的智驾算法需求出发,反向设计芯片架构。图灵芯片采用了DSA(特定领域架构),每一个计算单元都围绕小鹏的端到端感知与决策模型定制。据小鹏内部测算,图灵芯片的有效算力相较于上一代Orin芯片有近10倍的提升。小鹏声称其算力利用率可接近100%,这在通用芯片上是很难做到的,因为通用芯片在处理非AI任务时会有大量算力闲置。
图片源自:网络
DSA架构还有一个更重要的好处,那就是功耗控制。单颗图灵芯片功耗约30W,三颗集群总计80-100W。同样三颗Orin-X的系统功耗约120W,图灵芯片在同等算力水平下降低了约20%的功耗。对电动车来说,智驾系统节省的每一瓦功耗都会直接反映在续航里程上。
除了功耗,图灵芯片的内存配置也是为端到端大模型专门优化的,单颗图灵芯片配备64GB LPDDR5X内存,三颗集群共享216GB系统内存,带宽273GB/s。据小鹏官方确认,图灵芯片支持在本地运行高达300亿参数的大模型。这其实是一个关键的指标,由于智驾模型的参数量在过去两年内增长了数十倍,而且还在继续增长,如果芯片不支持足够大的本地内存,模型就只能被压缩或切片运行,这会影响推理精度。
更有意思的是,小鹏的三芯片集群方案同时承担智驾和座舱的AI计算,取消了传统架构中智驾芯片和座舱芯片的物理隔离。其中约1800 TOPS用于智能驾驶,400 TOPS用于座舱视觉语言模型。同一套硬件驱动两个系统,简化了整车电子电气架构,也摊薄了芯片的边际成本。
自研芯片的投入极高,前期动辄数亿美元,对一个年交付量不足30万辆的车企来说是重大的战略决策。但小鹏的逻辑是,只有在所有车型上都搭载这颗芯片,才能把成本摊薄、能力做强。图灵芯片已经在12万元级别的MONA M03到全系车型上实现了覆盖。这意味着小鹏的纯视觉方案在硬件成本上不仅省掉了激光雷达,还通过自研芯片替代外购芯片实现了进一步的降本。

扔掉激光雷达,摄像头凭什么能看得一样好?
算力和芯片解决了大脑的问题,但眼睛本身也必须足够好。纯视觉方案最大的挑战之一是极端光照条件下的感知能力,在逆光、暗光、隧道出入口等大光差场景下,传统车载摄像头很容易出现过曝或欠曝,导致图像信息大量丢失。激光雷达由于不依赖环境光,在这类场景下确实有天然优势。
小鹏应对这个问题方式是采用了AI鹰眼视觉方案。这套方案的最大技术亮点是采用了LOFIC架构的摄像头。LOFIC,全称是Lateral OverFlow Integration Capacitor(横向溢出集成电容技术),它的原理是在图像传感器的每个光电二极管旁边放置一个高密度电容。当光电二极管因为强光照射产生的电子数量超过了原本承载的上限,多余的光电子会流到相邻的电容里,而不是被丢弃。这就大幅提高了摄像头的动态范围,让它能在同时存在强光和阴影的场景中保留更多细节。

图片源自:网络
这项技术此前已在荣耀手机上率先应用,小鹏是第一个将其引入汽车行业的企业,在夜间、大逆光、雨雪天等复杂条件下,这套视觉方案的表现甚至比人眼更清晰。有数据显示,与上一代视觉系统相比,搭载LOFIC架构的鹰眼方案实时感知距离提升了125%,识别速度提升了40%,系统延迟减少了100毫秒。
感知硬件的提升必须和感知算法结合才能发挥作用,在算法层面,小鹏在2024年率先量产了国内第一个端到端智驾大模型。这套模型由三网合一的视觉感知神经网络XNet、基于神经网络的规划大模型XPlanner,以及大语言模型XBrain三个部分组成。
XNet是纯视觉方案中最重要的模块。它将动态XNet、静态XNet和纯视觉2K占用网络三者合一,用超过200万个网格对现实世界的可通行空间进行3D高真实度还原。所谓占用网络,指的是系统不是先识别出具体的物体,再判断能否通行,而是直接把三维空间划分为可通行和不可通行的区域。这种方法的优势在于能够处理训练数据中没有出现过的新型障碍物,因为系统不需要知道它是什么,只需要知道它占据了空间就行。

图片源自:网络
XBrain则引入了大语言模型的推理能力,让系统能理解潮汐车道、待转区、路牌文字等抽象信息。在传统方案中,这些复杂场景需要依赖高精地图来标注和识别。XBrain的加入使得系统即便在完全没有高精地图的区域,也能根据视觉信号做出正确的驾驶决策。
这三个模块协同工作,形成了从看到理解、从理解到决策的完整链条。2026年,小鹏进一步推出了第二代VLA大模型。它取消了传统架构中视觉-语言-动作的中间转译环节,实现了从视觉信号到驾驶动作的直接生成,决策延迟被压缩到80毫秒以内。第二代VLA推送首月,百公里人工接管次数环比就下降了25.87%。

图片源自:网络

数据和训练体系,为什么比硬件堆料更重要?
算力、芯片和感知硬件解决的是能不能跑的问题,但智驾系统的上限取决于训练数据的规模和质量。纯视觉方案对数据的依赖比激光雷达方案大得多,激光雷达至少能靠硬件在极端情况下兜底,纯视觉则完全靠算法从数据中学到对世界的理解。
小鹏为此构建了一套从云端到车端的完整训练和数据体系,称其为云端模型工厂。这套体系涵盖基座模型的预训练和后训练、模型蒸馏、车端模型训练与部署的全流程。云端训练的基础设施是万卡规模的计算集群,算力储备达到10 EFLOPS,集群利用率常年保持在90%以上,全链路迭代周期平均5天一次。
这个5天一迭代的频率意味着什么?在传统智驾开发模式下,算法团队修改模型后,通常需要数周甚至数月才能完成一轮完整的训练、测试和验证。5天一迭代意味着小鹏的模型能够以更快的速度吸收新的驾驶场景数据,不断改进表现。对于经常使用的高频路线,系统甚至能够做到千人千面的个性化优化。
正在训练的小鹏世界基座模型,参数规模达到720亿,这是一个以语言模型为骨干网络的多模态大模型,同时具备视觉理解能力、链式推理能力和动作生成能力。通过强化学习训练,这个基座模型可以不断自我进化,目标是能够处理全场景的自动驾驶问题,包括在训练数据中从未出现过的长尾场景。
720亿参数的基座模型显然无法直接部署在车端,即便图灵芯片的内存配置支持本地运行300亿参数的模型,也装不下这么庞大的模型。小鹏的解法是云端蒸馏,即在云端训练一个能力极强的超大模型,然后通过蒸馏技术把它压缩成适合车端计算资源的较小模型,再将这个蒸馏后的小模型部署上车。
蒸馏不是简单的参数减少,而是一个精巧的训练过程,目标是让小车端模型尽可能保留大云端模型的能力。如果把云端基座模型比作一位经验丰富的教授,那蒸馏到车端的模型就像是一个经过了教授严格训练、能独立处理各种路况的驾驶员。这种架构使车端模型保持轻量的同时,能力却能持续逼近云端模型的上限。
在仿真环节,小鹏还开发了世界模型X-World。这是一个基于视频扩散生成技术构建的可控多视角生成式模型,在给定历史视频流和驾驶动作的条件下,能够生成对应的未来多摄像头视频流。简单来说,它是一个能够想象未来数秒道路变化的物理世界仿真器,已被大量应用于第二代VLA的研发和验证,用于环境仿真与模型评估。为了提升仿真效率,小鹏还在2026年4月发布了X-Cache技术,能将世界模型的推理速度提升约2.7倍。
有了云端训练和仿真验证,剩下的就是数据来源。数据从哪来?来自大规模行驶的车辆。截至第二代VLA发布时,小鹏的智驾系统已基于折算超10亿公里的视频数据进行训练。2026年5月,第二代VLA推送满一个月,用户的智驾里程占比首次突破50%,这意味着在所有小鹏车主行驶的里程中,超过一半是由智驾系统完成的。
这个数字同时意味着,小鹏每天都能从实际驾驶中收集海量的高质量数据,而这些数据又源源不断地反哺到模型的训练和迭代中。数据越多,模型就越强;模型越强,用户越愿意使用智驾;使用越多,数据也就就越多。这背后的正向闭环,构成了小鹏转向纯视觉最根本的战略逻辑。
审核编辑 黄宇
相关文章
-
董事长官宣辞职!中百集团迎来高层更迭,新任董事候选人就位,公司上半年持续亏损
-
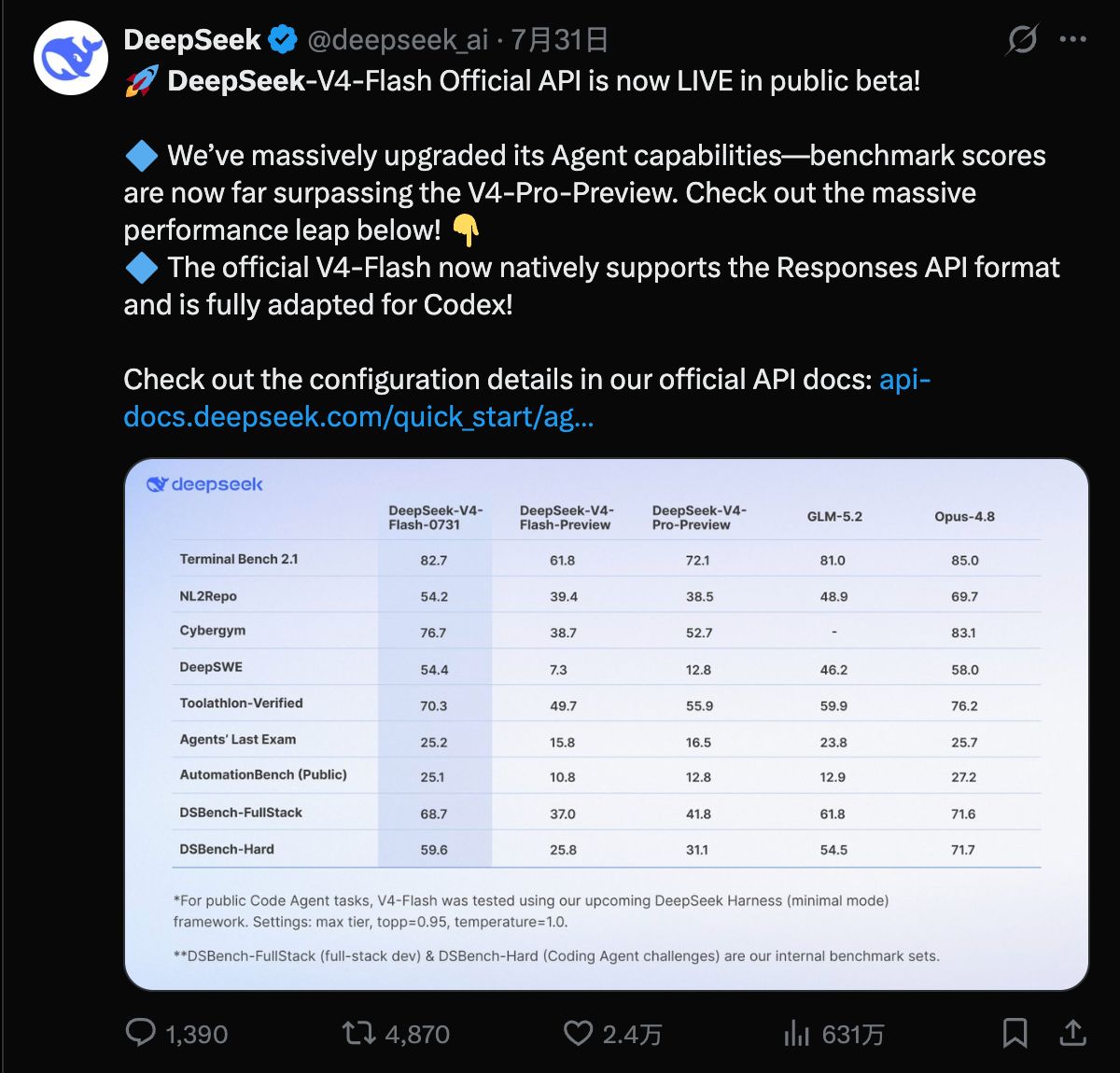
DeepSeek V4-Flash正式版来了!AI开发者实测:价格“很香” Agent能力直追顶级模型
-
亚马逊财报提振AI信心 美股期指走高 苹果盘前跌近8% | 今夜看点
-
伊称打击多个美军基地;宇树科技8月10日申购|21早新闻
-

标准落地即行动!光伏行业价格合规指导活动在即 统一成本核算“红绿灯”亮起
-
两大白酒巨头,同日高管调整
-
维琪科技正式登陆北交所 重新定义化妆品原料创新
-
最新!拆解7万亿银行系公募